|
I am a research scientist at MIT-IBM Watson AI Lab, where I work on computer vision and machine learning. I received my Ph.D. from UC Riverside in 2018, under the supervision of Prof. Amit K. Roy-Chowdhury. During Ph.D., I was very fortunate to have interned at NEC Labs, Adobe Research and Siemens Research. Email / CV / Google Scholar / LinkedIn |

|
|
My research interests mainly lie in the areas of computer vision, machine learning and more recently natural language processing, with a special focus on efficient AI, including data efficiency and model efficiency. I am also interested in image/video understanding, unsupervised/self-supervised representation learning and multimodal learning. |
|
|
|
|
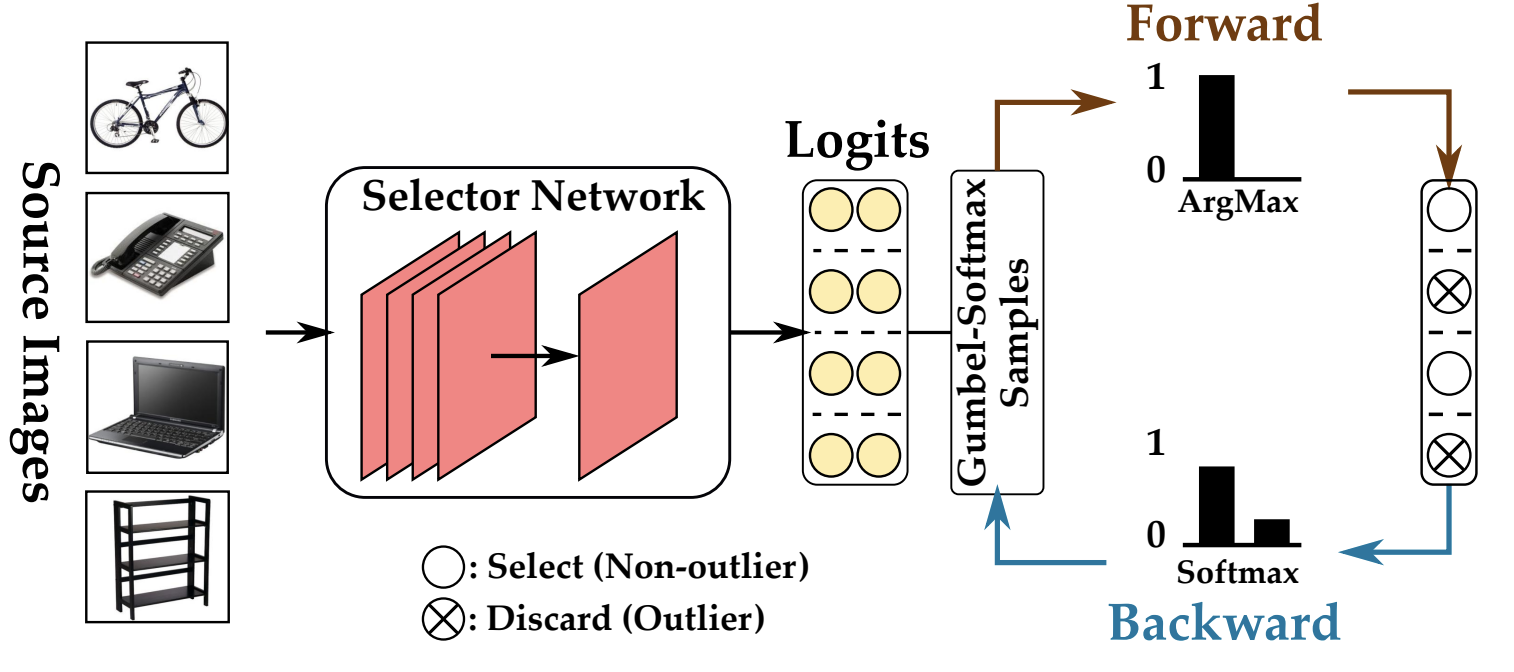
Aadarsh Sahoo, Rameswar Panda, Rogerio Feris, Kate Saenko, Abir Das Winter Conference on Applications of Computer Vision (WACV), 2023 NeurIPS Workshop on Distribution Shifts (NeurIPS-W), 2021 [PDF] Best Paper Honorable Mention [Project Page] [Code] [Supplementary Material] We develop a new framework for learning discriminative and invariant feature representation while preventing intrinsic negative transfer in partial domain adaptation. |
|
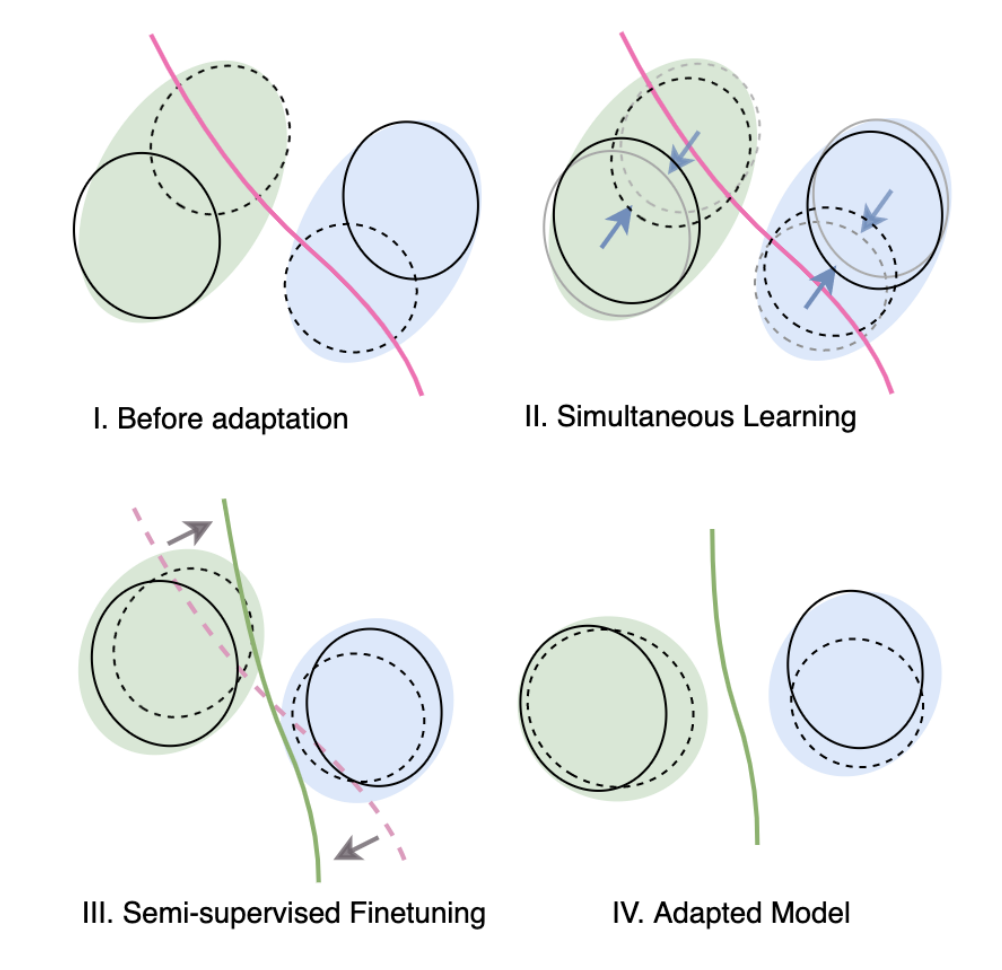
Md Mahmudur Rahman, Rameswar Panda, Mohammad Arif Ul Alam Winter Conference on Applications of Computer Vision (WACV), 2023 We propose an auto-encoder-based approach combined with a simultaneous learning scheme to align source and target features for semi-supervised domain adaptation. |
|
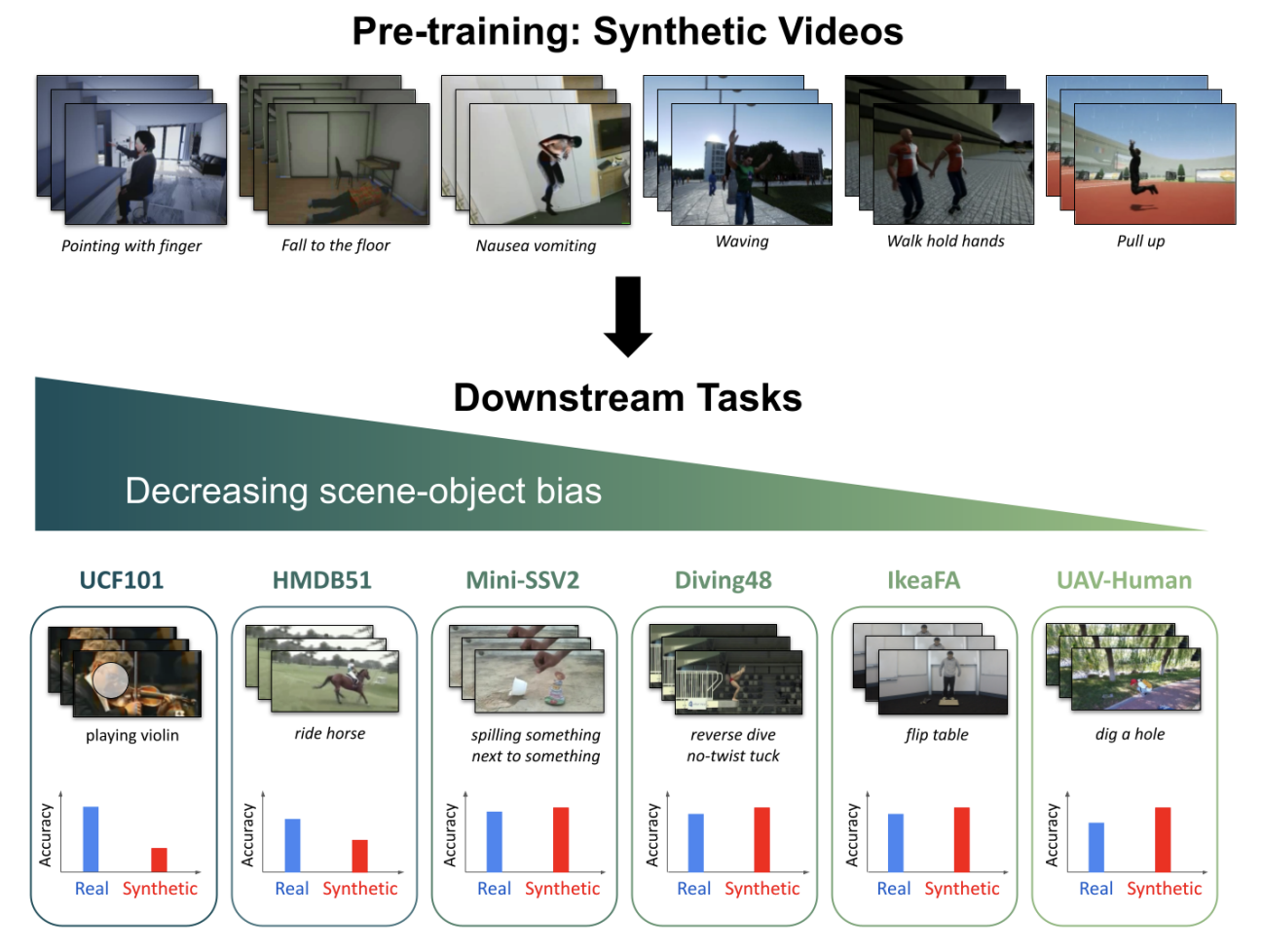
Yo-whan Kim, Samarth Mishra, SouYoung Jin, Rameswar Panda, Hilde Kuehne, Leonid Karlinsky, Venkatesh Saligrama, Kate Saenko, Aude Oliva, Rogerio Feris Neural Information Processing Systems Datasets (NeurIPS), 2022 [Dataset] [Supplementary Material] We propose a new benchmark, SynAPT, for studying the transferability of synthetic video representations for action recognition. |

|
Amit Alfassy, Assaf Arbelle, Oshri Halimi, Sivan Harary, Roei Herzig, Eli Schwartz, Rameswar Panda, Michele Dolfi, Christoph Auer, Peter Staar, Kate Saenko, Rogerio Feris, Leonid Karlinsky Neural Information Processing Systems Datasets (NeurIPS), 2022 [Dataset] [Supplementary Material] We introduce FETA benchmark to understand technical documentations, via learning to match their graphical illustrations to corresponding language descriptions. |
|
Abhin Shah, Yuheng Bu, Joshua K Lee, Subhro Das, Rameswar Panda, Prasanna Sattigeri, Gregory Wornell International Conference on Machine Learning (ICML), 2022 We demonstrate the performance disparities across different subgroups for selective regression and develop novel methods to mitigate such disparities. |
|
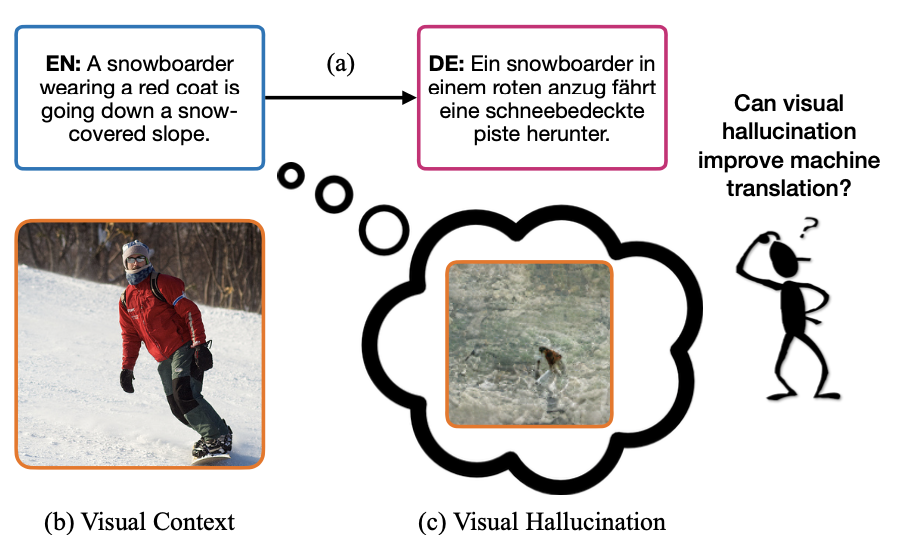
Yi Li, Rameswar Panda, Yoon Kim, Chun-Fu (Richard) Chen, Rogerio Feris, David Cox, Nuno Vasconcelos IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022 [Project Page] [Code] [Supplementary Material] We introduce a visual hallucination framework which requires only source sentences at inference time and instead uses hallucinated visual representations for multimodal machine translation. |
|
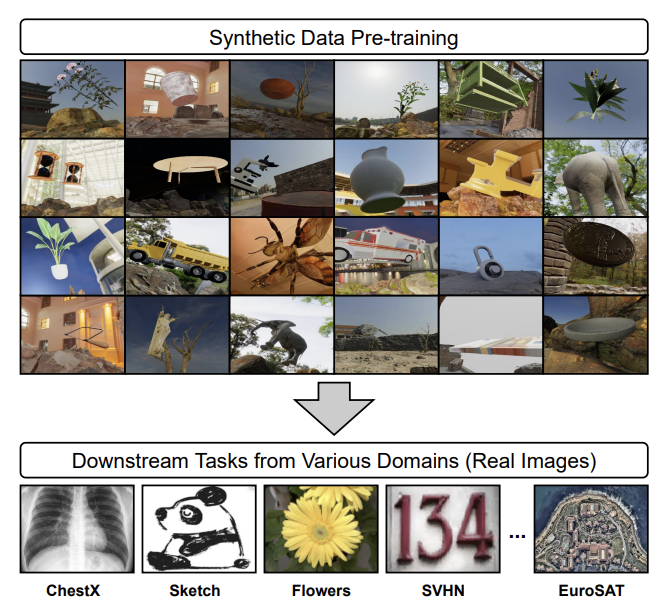
Samarth Mishra, Rameswar Panda, Cheng Perng Phoo, Chun-Fu (Richard) Chen, Leonid Karlinsky, Kate Saenko, Venkatesh Saligrama, Rogerio Feris IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022 [Project Page] [Code] [Supplementary Material] We propose a unified model mapping downstream task representations to optimal simulation parameters to generate synthetic pre-training data for them. |
|
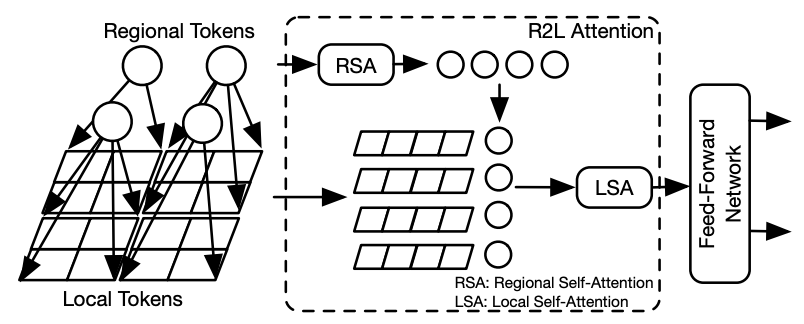
Chun-Fu (Richard) Chen, Rameswar Panda, Quanfu Fan International Conference on Learning Representations (ICLR), 2022 [Code] We propose a new architecture that adopts the pyramid structure and employ a regional-to-local attention rather than global self-attention in vision transformers. |
|
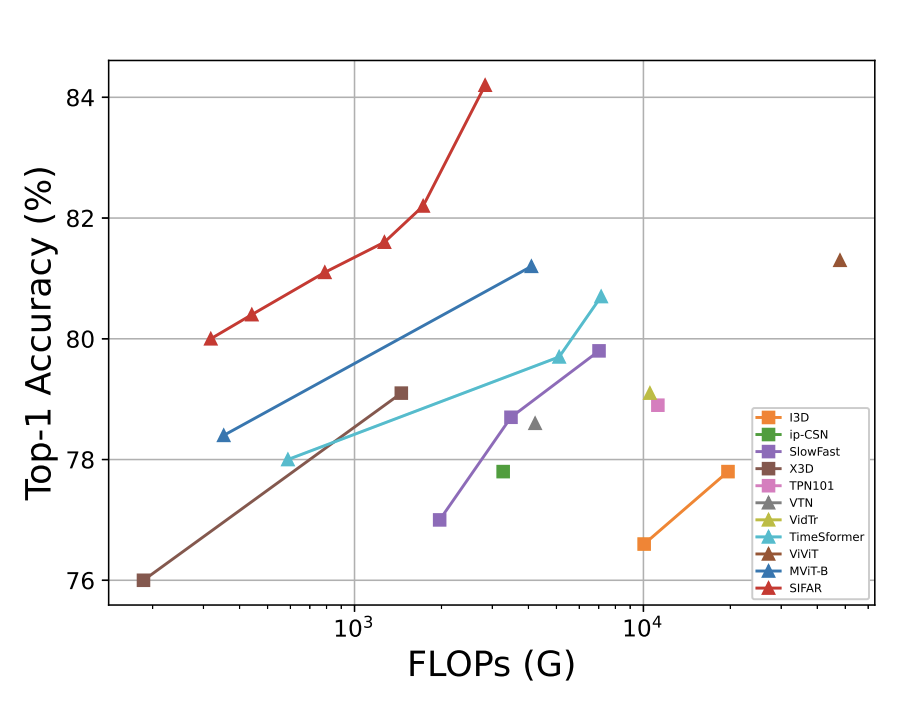
Quanfu Fan, Chun-Fu (Richard) Chen, Rameswar Panda International Conference on Learning Representations (ICLR), 2022 [Code] We introduce the idea of rearranging input video frames into super images to re-purpose an image classifer for video action recognition. |
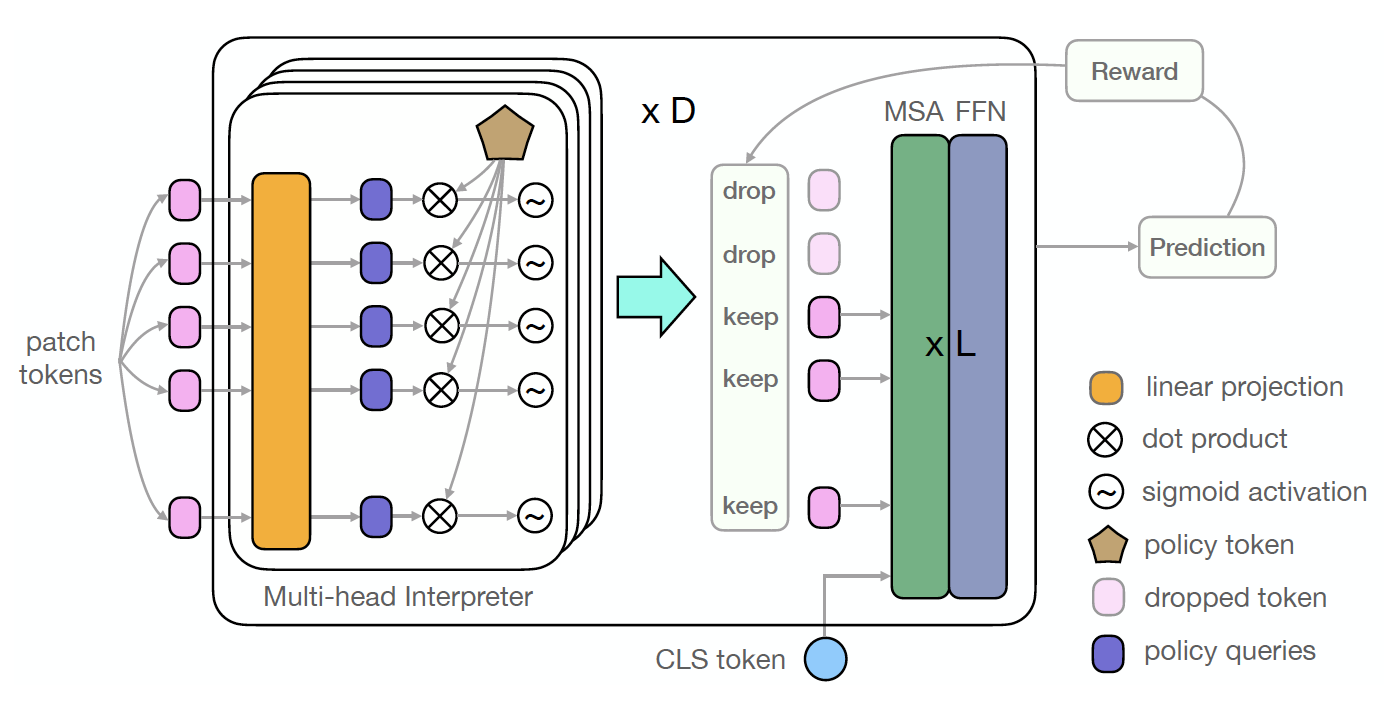
|
Bowen Pan, Rameswar Panda, Yifan Jiang, Zhangyang Wang, Rogerio Feris, Aude Oliva Neural Information Processing Systems (NeurIPS), 2021 [Project Page] [Code] [Supplementary Material] We introduce an input-dependent and interpretable dynamic inference framework for vision transformer, which adaptively decides the patch tokens to compute per input instance. |
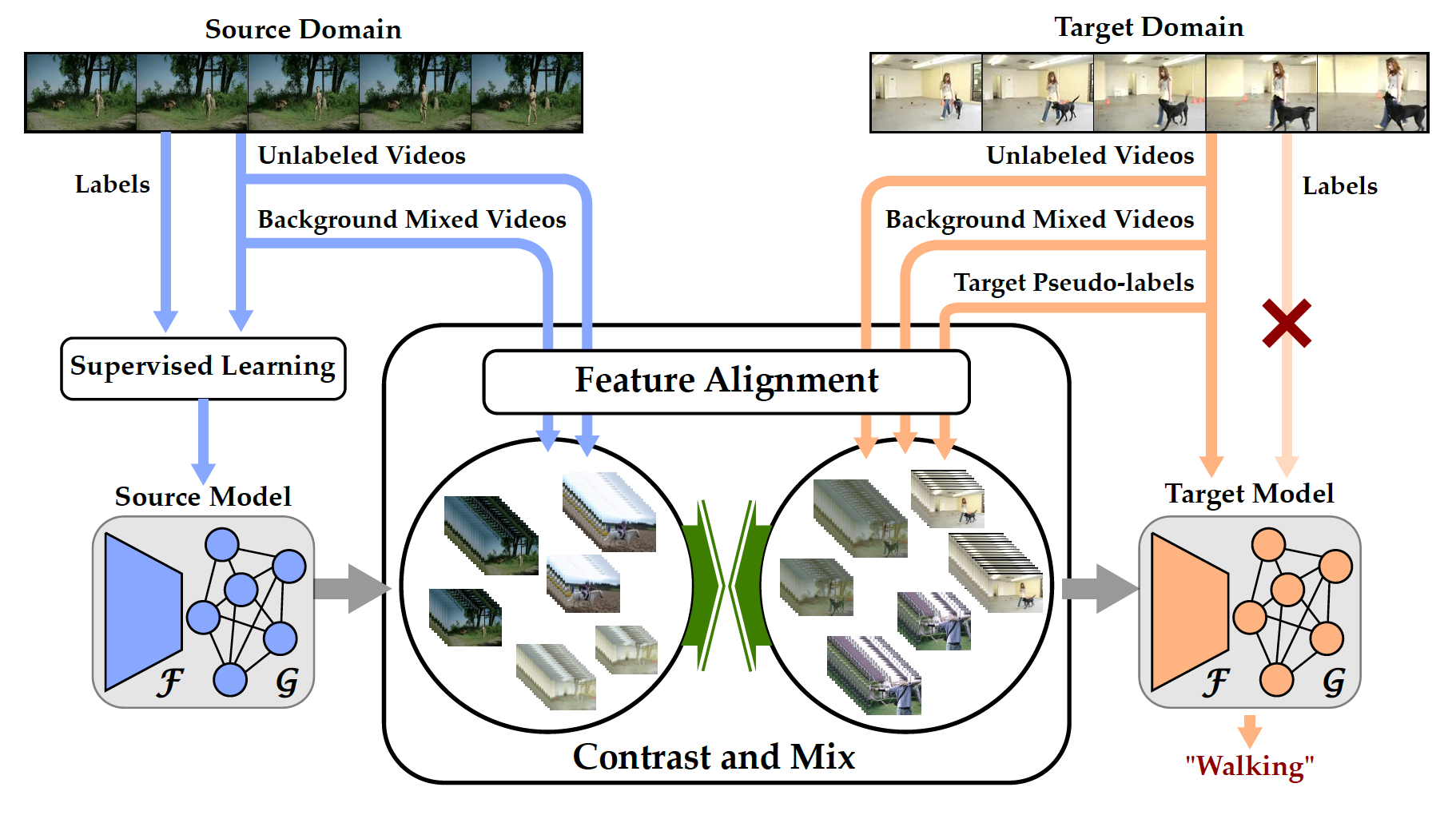
|
Aadarsh Sahoo, Rutav Shah, Rameswar Panda, Kate Saenko, Abir Das Neural Information Processing Systems (NeurIPS), 2021 [Project Page] [Code] [Supplementary Material] We propose a new contrastive learning framework that aims to learn discriminative invariant feature representations for unsupervised video domain adaptation. |
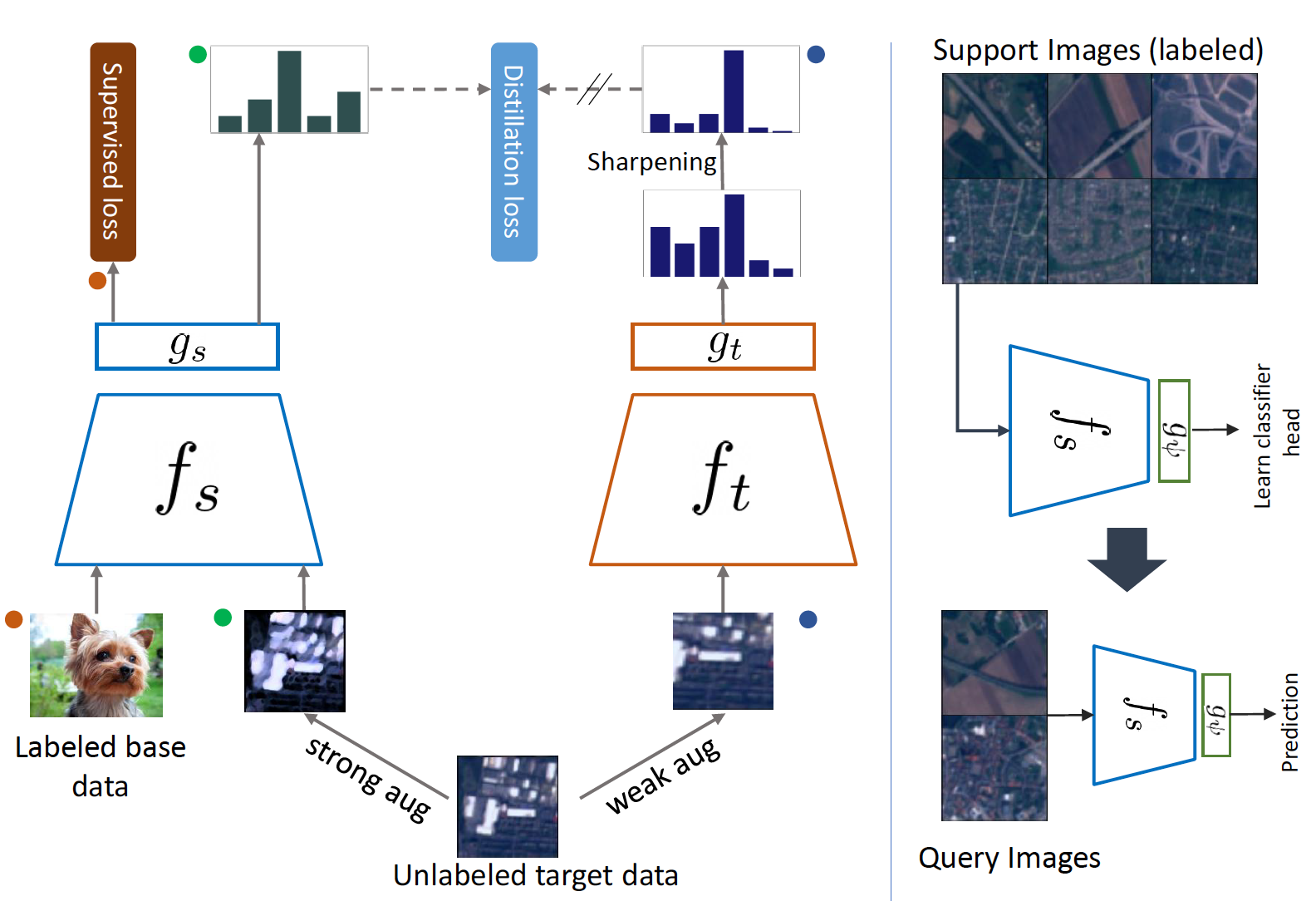
|
Ashraful Islam, Chun-Fu (Richard) Chen, Rameswar Panda, Leonid Karlinsky, Rogerio Feris, Richard Radke Neural Information Processing Systems (NeurIPS), 2021 CVPR Workshop on Learning from Limited or Imperfect Data (CVPR-W), 2021 [PDF] [Code] [Supplementary Material] We address the problem of cross-domain few-shot learning by proposing a simple distillation-based method to facilitate unlabeled images from the novel dataset. |
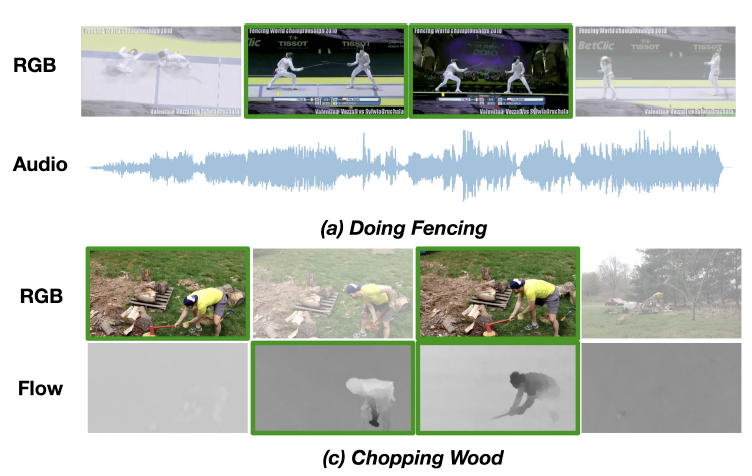
|
Rameswar Panda*, Chun-Fu (Richard) Chen*, Quanfu Fan, Ximeng Sun, Kate Saenko, Aude Oliva, Rogerio Feris International Conference on Computer Vision (ICCV), 2021 Invited Paper Talk at CVPR Workshop on Sight and Sound (CVPR-W), 2021 [Video] [Project Page] [Code] [Supplementary Material] We propose an adaptive multi-modal learning framework that selects on-the-fly the optimal modalities for each segment conditioned on the input for efficient video recognition. |

|
Ximeng Sun, Rameswar Panda, Chun-Fu (Richard) Chen, Aude Oliva, Rogerio Feris, Kate Saenko International Conference on Computer Vision (ICCV), 2021 [Project Page] [Code] [Supplementary Material] We introduce video instance-aware quantization that decides what precision should be used on a per frame basis for efficient video inference. |
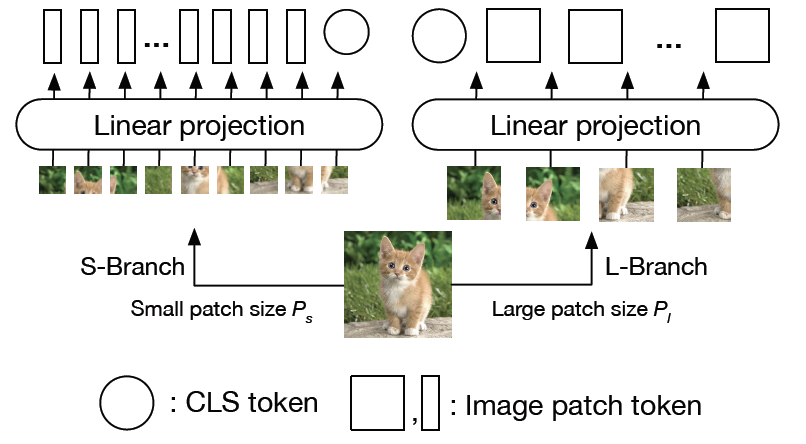
|
Chun-Fu (Richard) Chen, Quanfu Fan, Rameswar Panda International Conference on Computer Vision (ICCV), 2021 (Oral) [Code] [Supplementary Material] We develop a dual-branch vision transformer by combining image patches of different sizes to extract multi-scale feature representations for image classification. |
|
|
Ashraful Islam, Chun-Fu (Richard) Chen, Rameswar Panda, Leonid Karlinsky, Richard Radke, Rogerio Feris International Conference on Computer Vision (ICCV), 2021 [Code] [Supplementary Material] We conduct extensive analysis on the transferability of contrastive learning on the downstream image classification, few-shot recognition, and object detection tasks. |
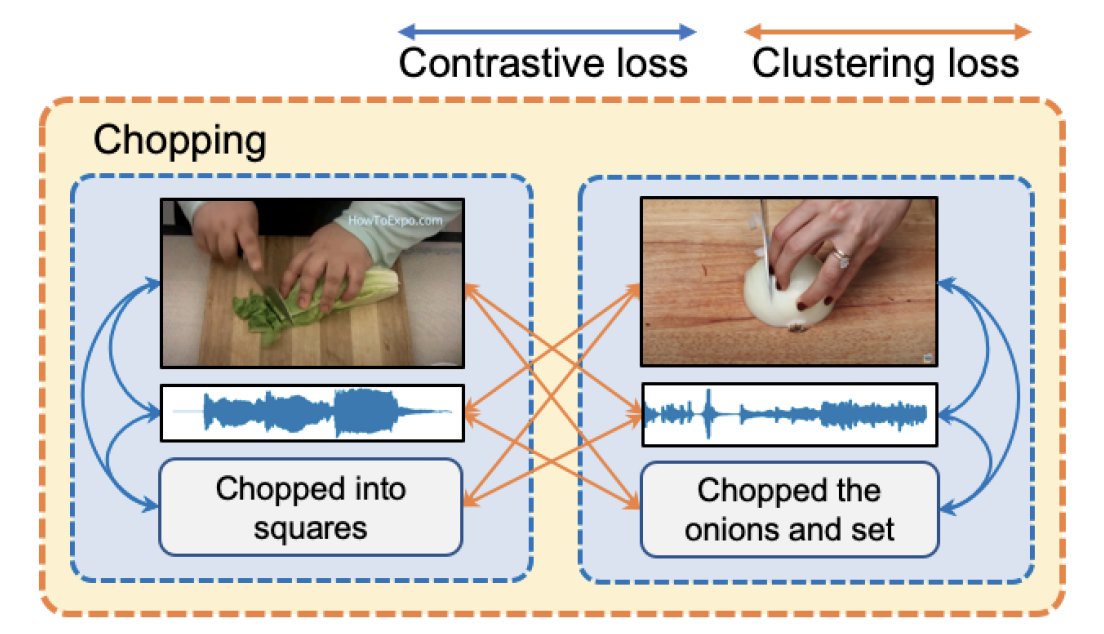
|
Brian Chen, Andrew Rouditchenko, Kevin Duarte, Hilde Kuehne, Samuel Thomas, Angie Boggust, Rameswar Panda, Brian Kingsbury, Rogerio Feris, David Harwath, James Glass, Michael Picheny, Shih-Fu Chang International Conference on Computer Vision (ICCV), 2021 CVPR Workshop on Sight and Sound (CVPR-W), 2021 [PDF] [Code] We extend the concept of instance-level contrastive learning with a multimodal clustering step in the training pipeline to capture semantic similarities across modalities. |
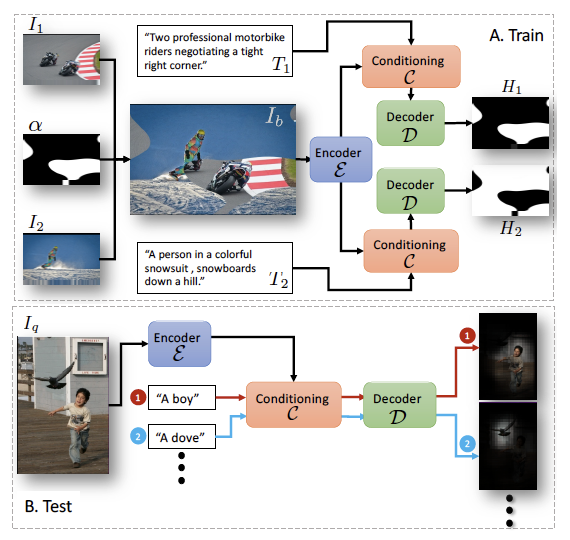
|
Assaf Arbelle, Sivan Doveh, Amit Alfassy, Joseph Shtok, Guy Lev, Eli Schwartz, Hilde Kuehne, Hila Barak Levi, Prasanna Sattigeri, Rameswar Panda, Chun-Fu (Richard) Chen, Alex Bronstein, Kate Saenko, Shimon Ullman, Raja Giryes, Rogerio Feris, Leonid Karlinsky International Conference on Computer Vision (ICCV), 2021 (Oral) We propose a detector-free approach for weakly supervised grounding by learning to separate randomly blended images conditioned on the corresponding texts. |
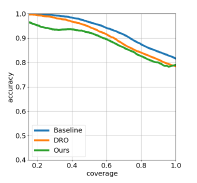
|
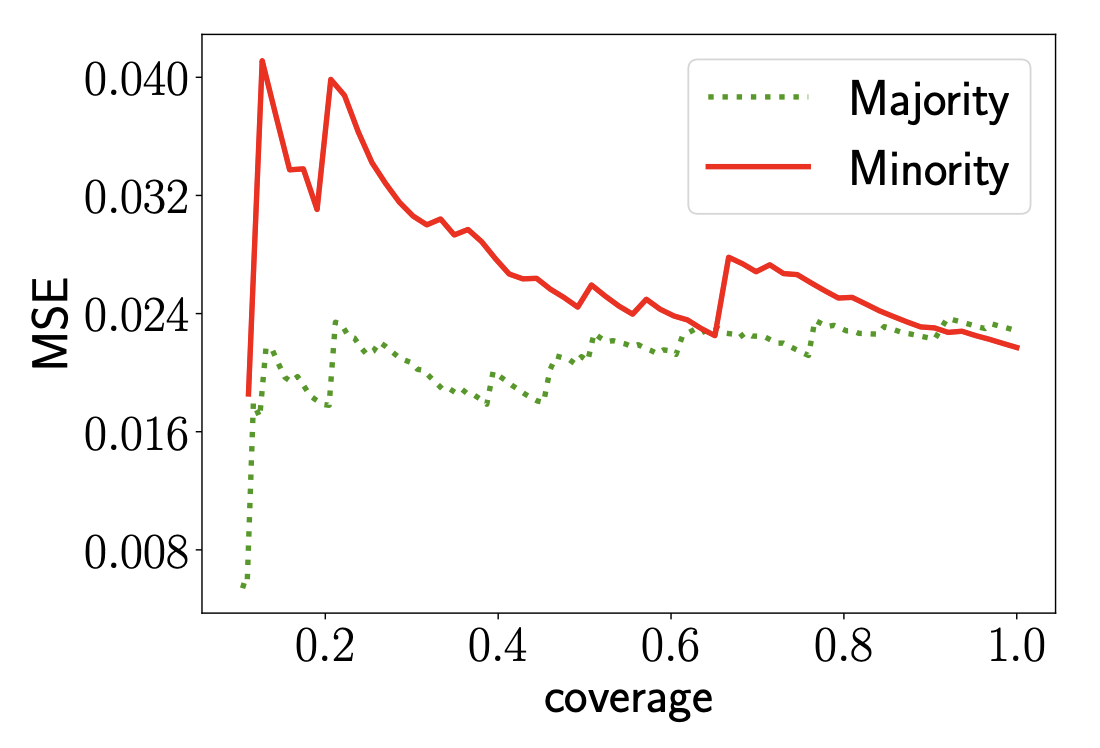
Joshua Lee, Yuheng Bu, Deepta Rajan, Prasanna Sattigeri, Rameswar Panda, Subhro Das, Gregory Wornell International Conference on Machine Learning (ICML), 2021 (Oral) We prove that sufficiency can be used to train fairer selective classifiers which ensure that precision always increases as coverage is decreased for all groups. |
|
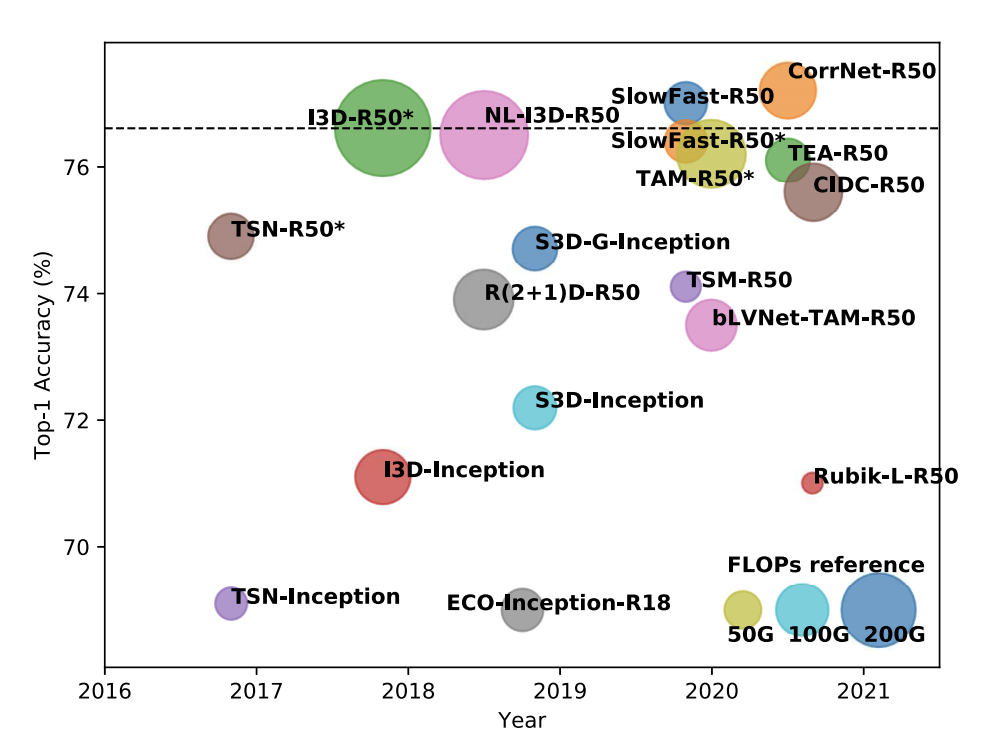
Chun-Fu (Richard) Chen*, Rameswar Panda*, Kandan Ramakrishnan, Rogerio Feris, John Cohn, Aude Oliva, Quanfu Fan* IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021 [Code] [Supplementary Material] We develop a unified framework for action recognition models and systematically compare them to better understand the differences and spatio-temporal behavior on large-scale datasets. |
|
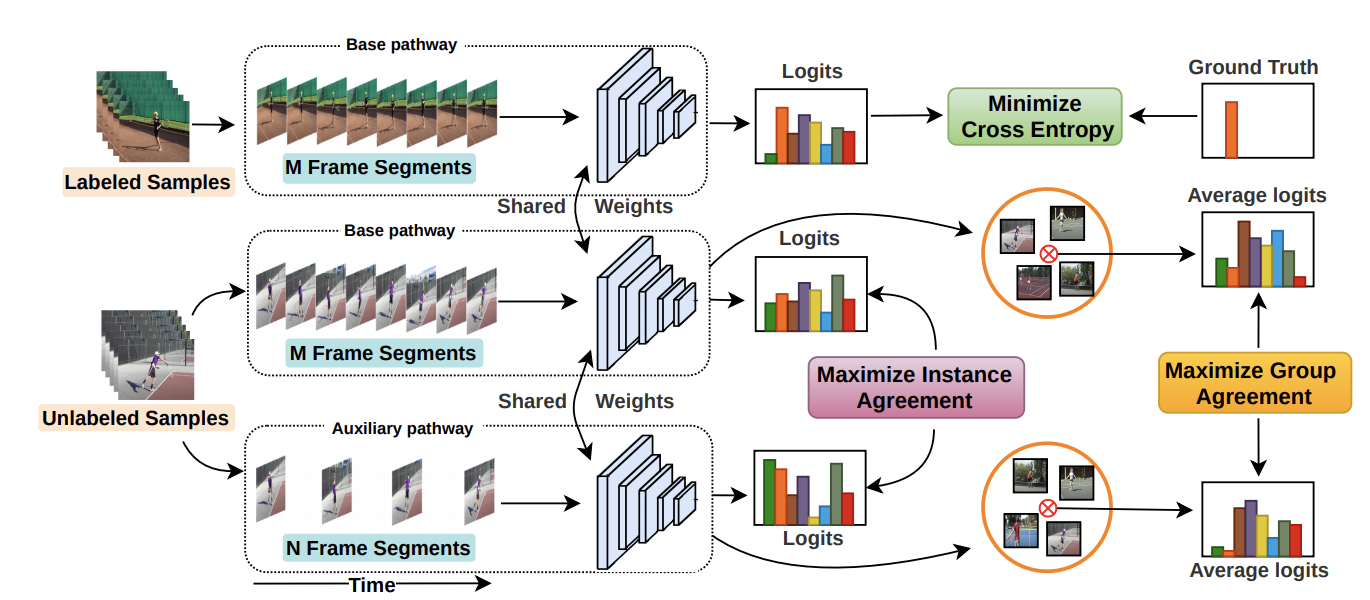
Ankit Singh, Omprakash Chakraborty, Ashutosh Varshney, Rameswar Panda, Rogerio Feris, Kate Saenko, Abir Das IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021 [Project Page] [Code] [Supplementary Material] We propose a temporal contrastive learning framework for semi-supervised action recognition by using contrastive losses between different videos and groups of videos with similar actions. |
|
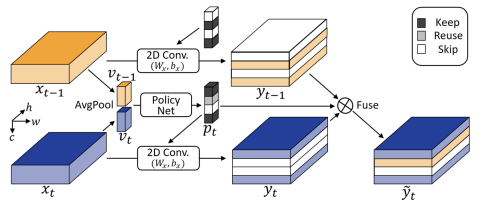
Yue Meng, Rameswar Panda, Chung-Ching Lin, Prasanna Sattigeri, Leonid Karlinsky, Kate Saenko, Aude Oliva, Rogerio Feris International Conference on Learning Representations (ICLR), 2021 [Project Page] [Code] We introduce an adaptive temporal fusion network that dynamically fuses channels from current and past feature maps for strong temporal modelling in action recognition. |
|
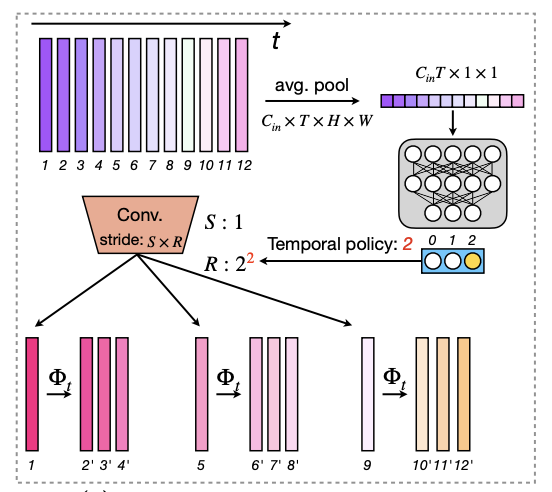
Bowen Pan, Rameswar Panda, Camilo Fosco, Chung-Ching Lin, Alex Andonian, Yue Meng, Kate Saenko, Aude Oliva, Rogerio Feris International Conference on Learning Representations (ICLR), 2021 [Project Page] [Code] We propose an input-dependent adaptive framework for efficient video recognition that automatically decides what feature maps to compute per input instance. |
|
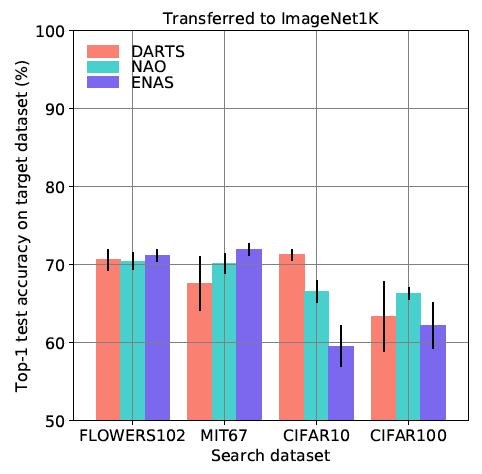
Rameswar Panda, Michele Merler, Mayoore Jaiswal, Hui Wu, Kandan Ramakrishnan, Ulrich Finkler, Richard Chen, Minsik Cho, Rogerio Feris, David Kung, Bishwaranjan Bhattacharjee AAAI Conference on Artificial Intelligence (AAAI), 2021 We analyze the architecture transferability of different NAS methods by performing a series of experiments on several large scale image benchmarks. |
|
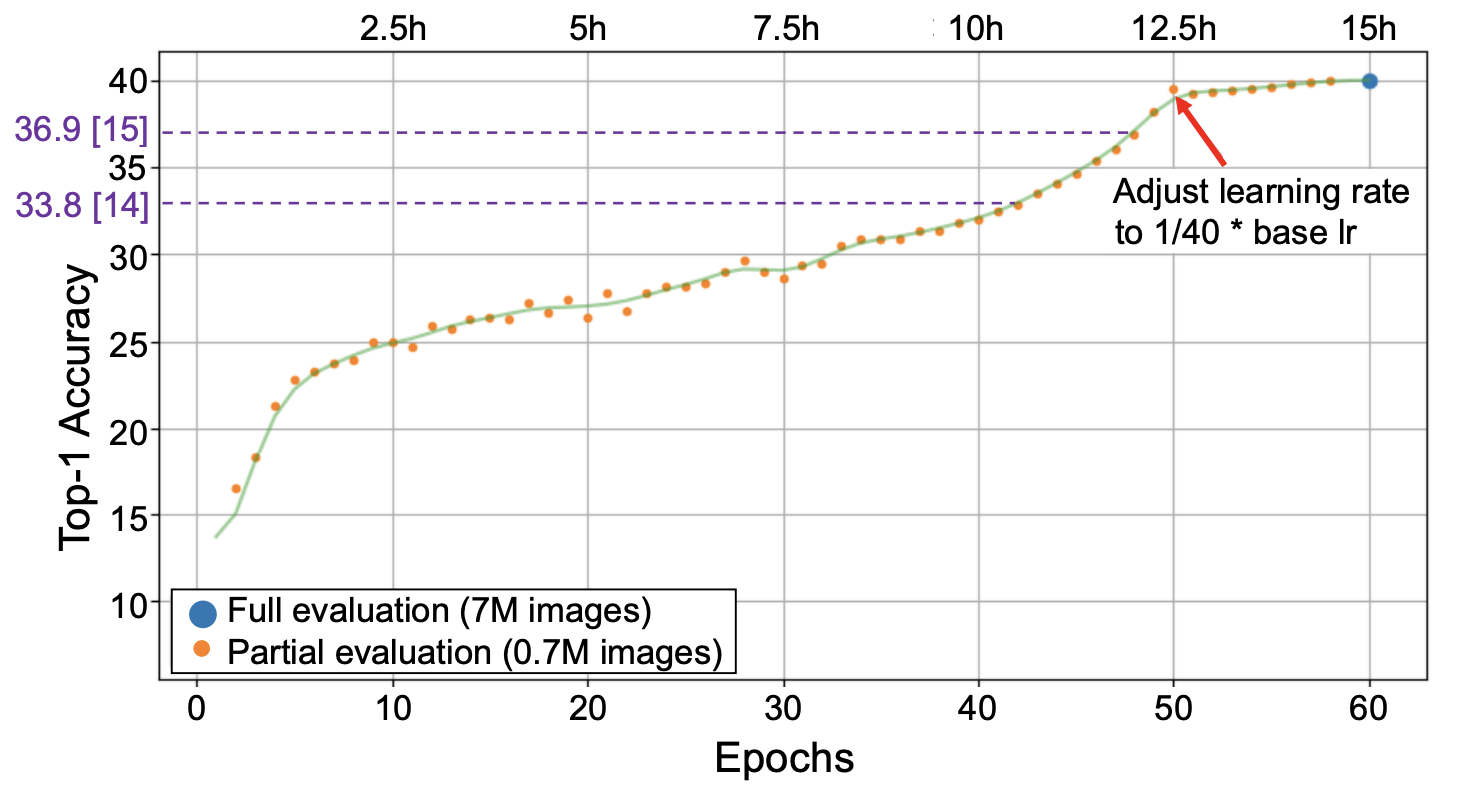
Ulrich Finkler, Michele Merler, Rameswar Panda, Mayoore Jaiswal, Hui Wu, Kandan Ramakrishnan, Chun-Fu Chen, Minsik Cho, David Kung, Rogerio Feris, Bishwaranjan Bhattacharjee AAAI Workshop on Meta-Learning for Computer Vision (AAAI-W), 2021 We propose a NAS method based on polyharmonic splines that can perform architecture search directly on large scale image datasets like ImageNet22K. |
|
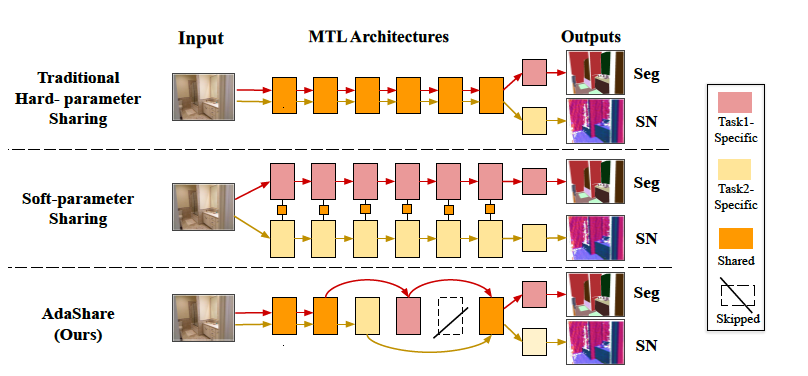
Ximeng Sun, Rameswar Panda, Rogerio Feris, Kate Saenko Neural Information Processing Systems (NeurIPS), 2020 [Project Page] [Code] [Supplementary Material] We propose a novel approach for adaptively determining the feature sharing pattern across multiple tasks (what layers to share across which tasks) in deep multi-task learning. |
|
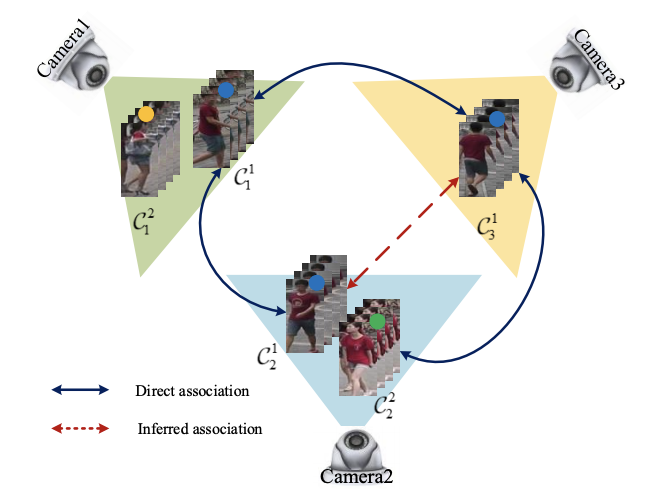
Xueping Wang, Rameswar Panda, Min Liu, Yaonan Wang, Amit K. Roy-Chowdhury IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), 2020 We propose a consistent cross-view matching framework, in which global camera network constraints are exploited to address the problem of unsupervised video-based re-identification. |
|
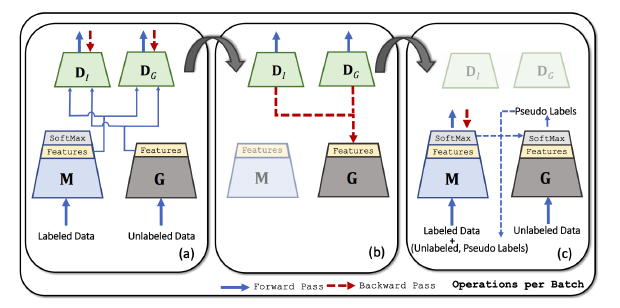
Akash Gupta*, Rameswar Panda*, Sujoy Paul, Jianming Zhang, Amit K. Roy-Chowdhury ACM Multimedia (MM), 2020 [Project Page] [Code] We present a novel adversarial framework for transferring knowledge from internet-scale unlabeled data to improve the performance of a classifier on a given visual recognition task. |
|
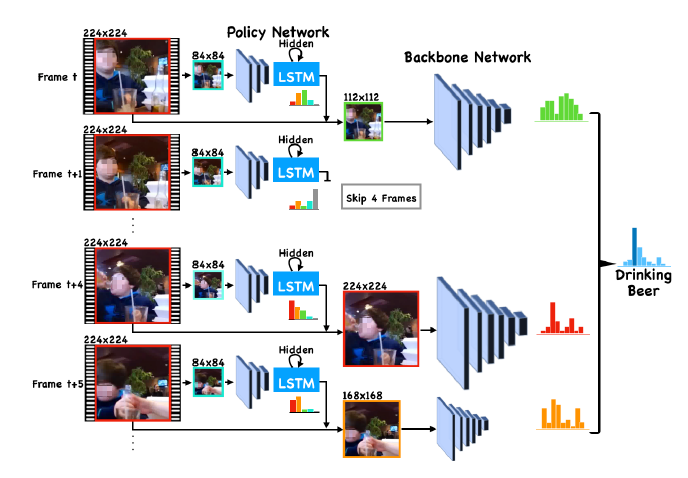
Yue Meng, Chung-Ching Lin, Rameswar Panda, Prasanna Sattigeri, Leonid Karlinsky, Aude Oliva, Kate Saenko, Rogerio Feris European Conference on Computer Vision (ECCV), 2020 [Project Page] [Code] We propose an adaptive approach to select optimal resolution for each frame conditioned on the input for efficient action recognition in long untrimmed video. |
|
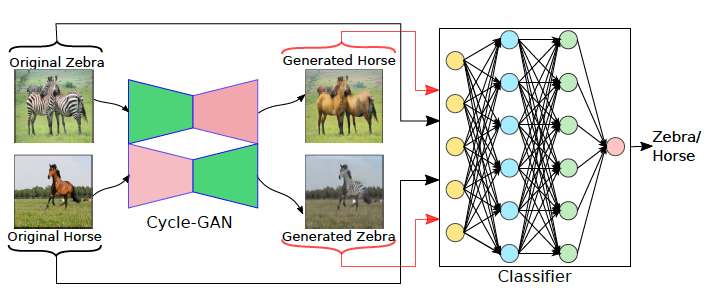
Aadarsh Sahoo, Ankit Singh, Rameswar Panda, Rogerio Feris, Abir Das ECCV Workshop on Imbalance Problems in Computer Vision (ECCV-W), 2020 We introduce a joint dataset repairment strategy by combining classifier with a GAN that makes up for the deficit of training examples from the minority class by producing additional examples. |
|
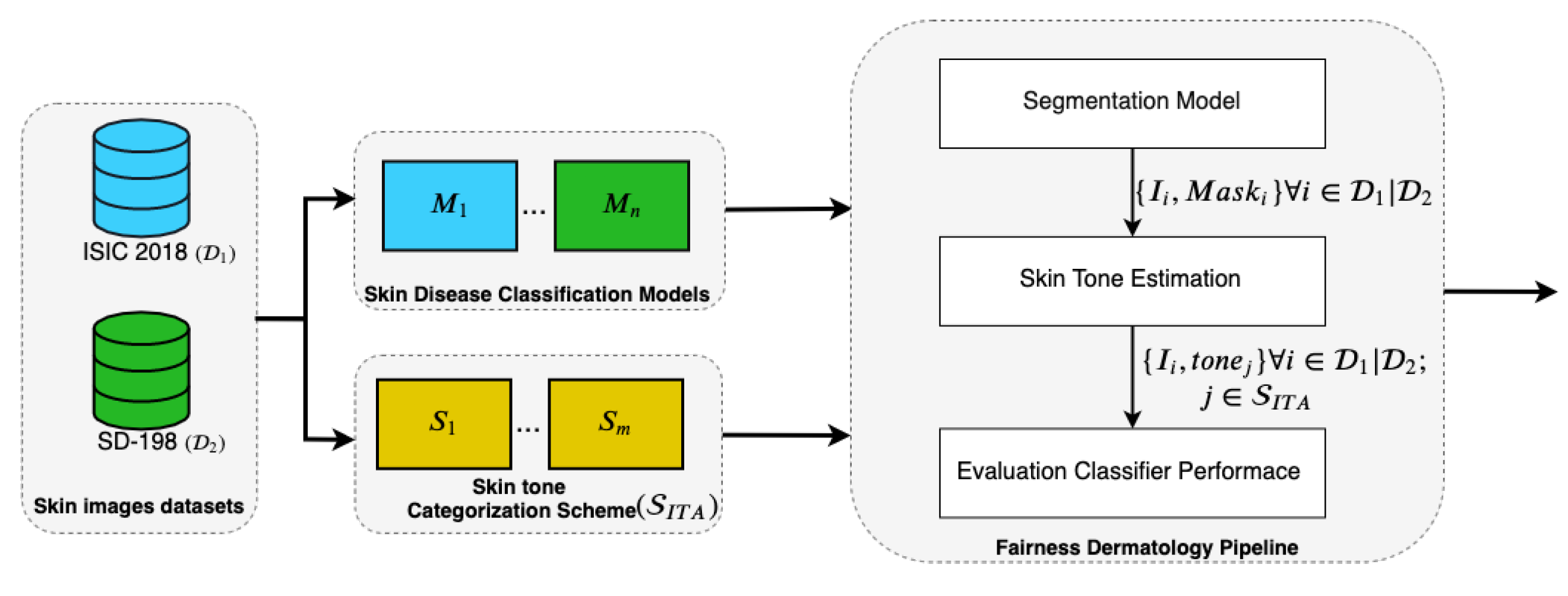
Newton M. Kinyanjui, Timothy Odonga, Celia Cintas, Noel C. F. Codella, Rameswar Panda, Prasanna Sattigeri, Kush R. Varshney Medical Image Computing and Computer Assisted Interventions (MICCAI), 2020 We present an approach to estimate the consistency in performance of classifiers across populations with varying skin tones in skin disease benchmarks. |
|
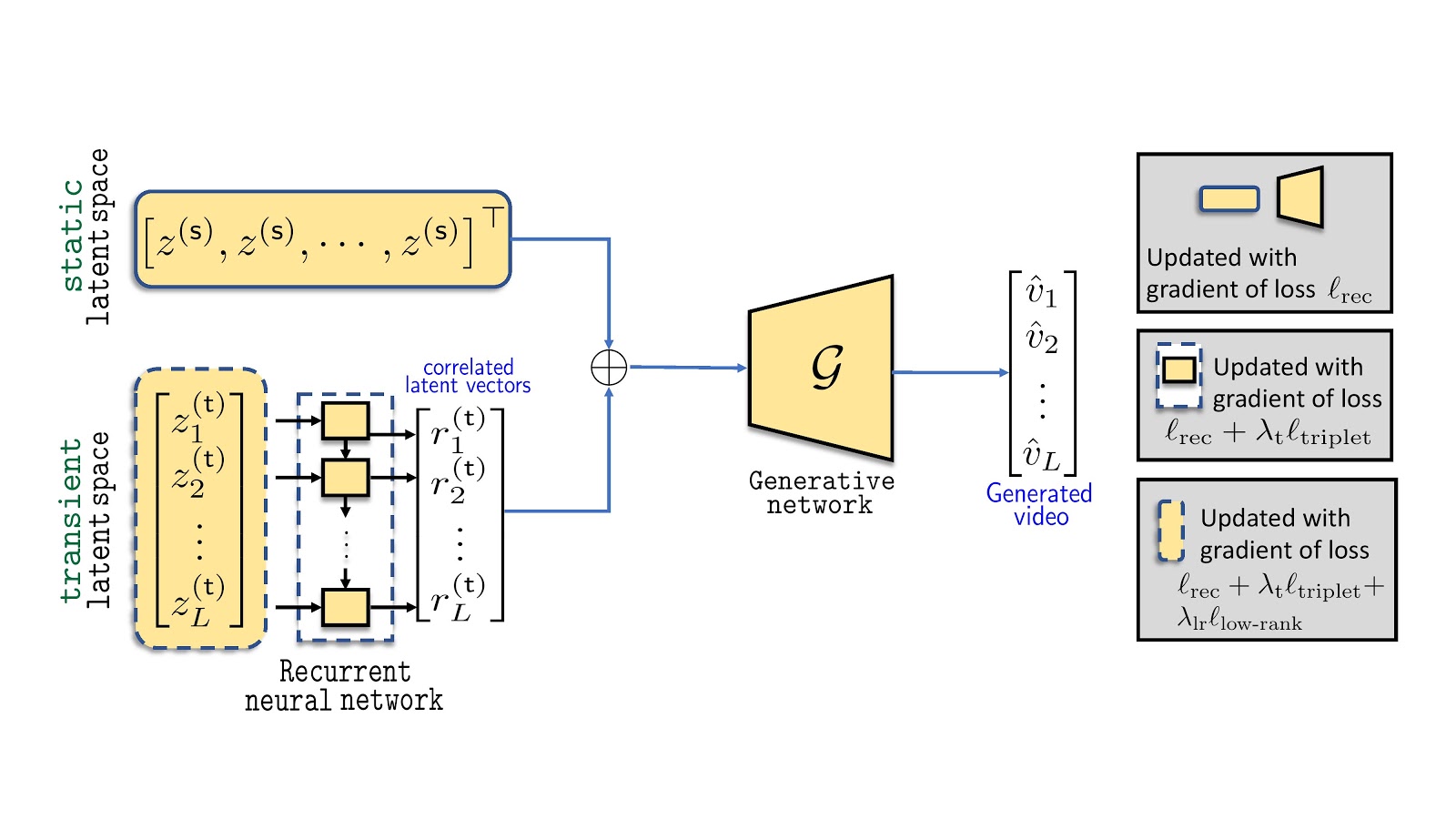
Abhishek Aich, Akash Gupta, Rameswar Panda, Rakib Hyder, Salman Asif, Amit K. Roy-Chowdhury IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020 [Project Page] [Code] We introduce a novel non-adversarial framework for generating a wide range of diverse videos from latent noise vectors without any any conditional input reference frame. |
|
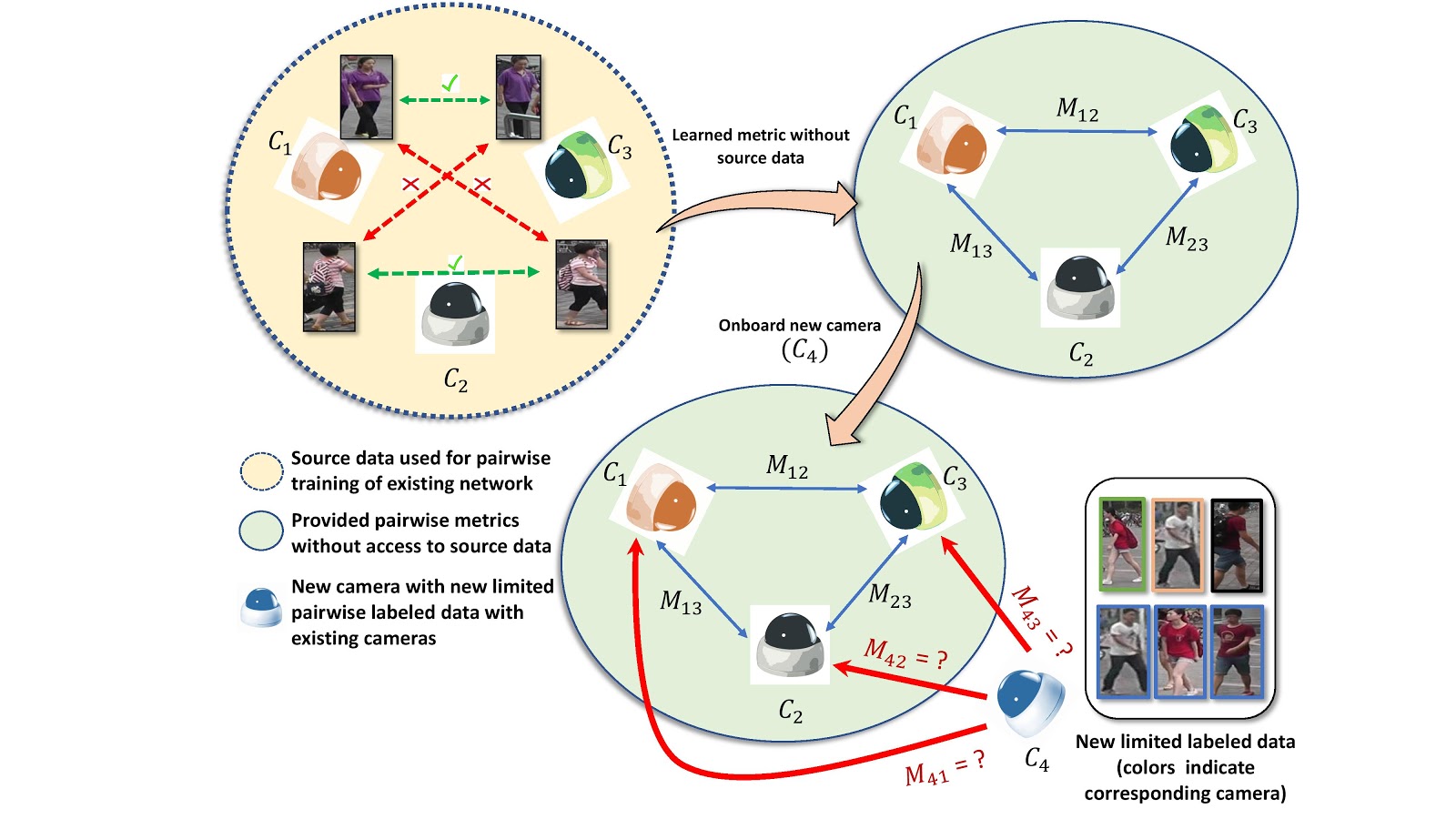
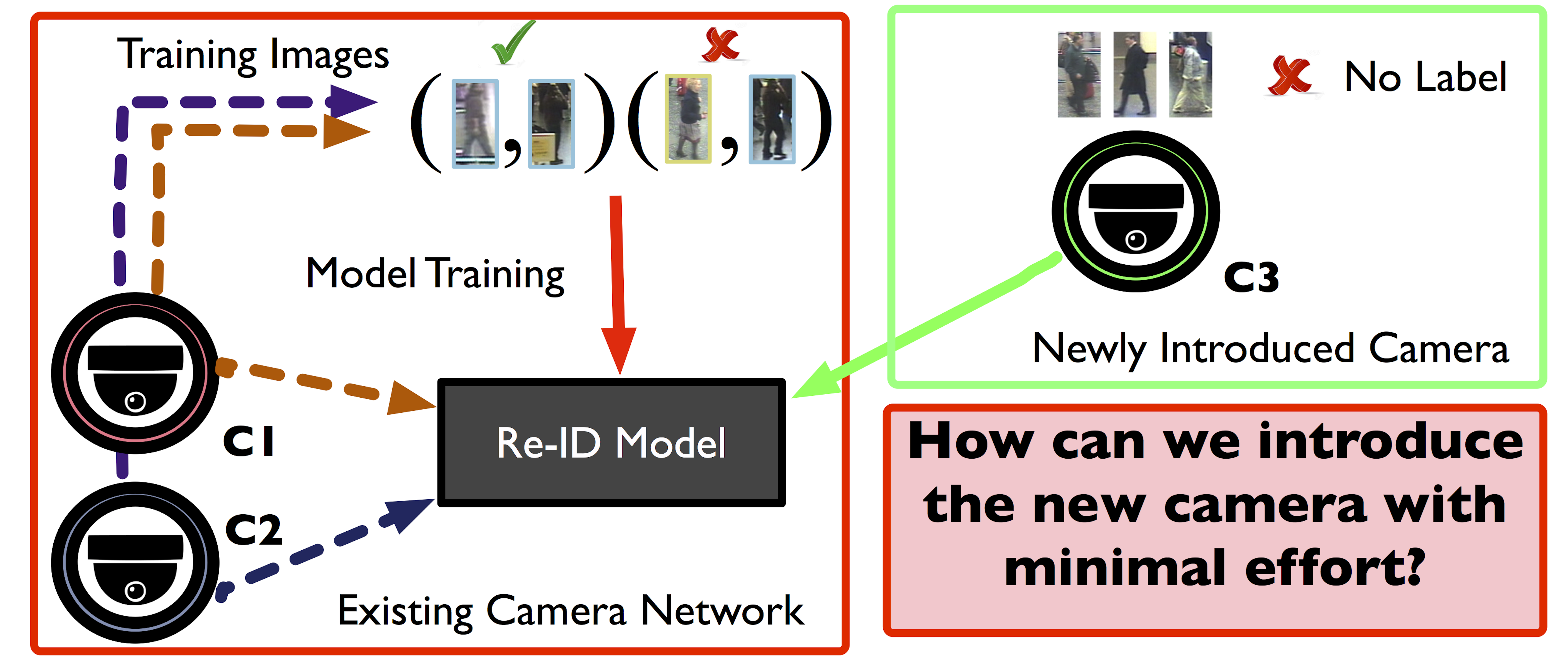
Sk Miraj Ahmed, Aske R. Lejbolle, Rameswar Panda, Amit K. Roy-Chowdhury IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020 We propose an approach to swiftly on-board new camera(s) in an existing re-id network using only source models and limited labeled data, but without having access to source camera data. |
|
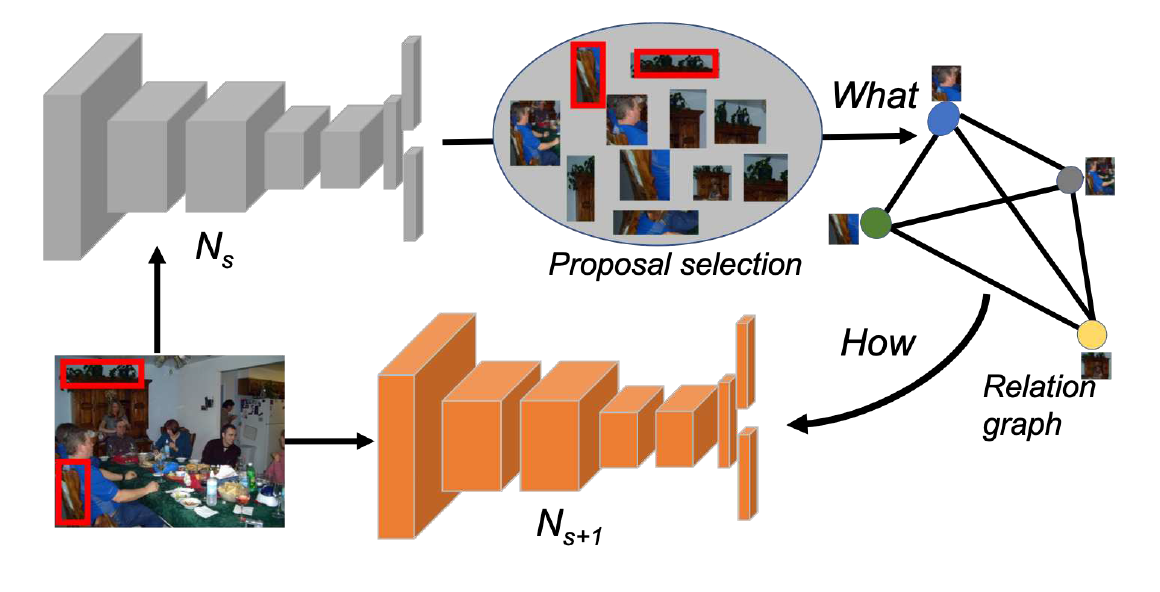
Kandan Ramakrishnan, Rameswar Panda, Quanfu Fan, John Henning, Aude Oliva, Rogerio Feris CVPR Workshop on Continual Learning in Computer Vision (CVPR-W), 2020 We introduce a novel approach that focuses on object relations to effectively transfer knowledge for minimizing the effect of catastrophic forgetting in incremental learning of object detectors. |

|
Rameswar Panda, Amran Bhuiyan, Vittorio Murino, Amit K. Roy-Chowdhury Pattern Recognition (PR), 2019 This paper extends our CVPR 2017 paper providing a new source-target selective adaptation strategy and rigorous experiments on more person re-id datasets. |

|
Niluthpol C. Mithun, Rameswar Panda, Amit K. Roy-Chowdhury IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), 2019 This paper extends our MM 2016 paper where we employ a joint visual-semantic space to simultaneously utilize both images and text from the web for dataset construction. |
|
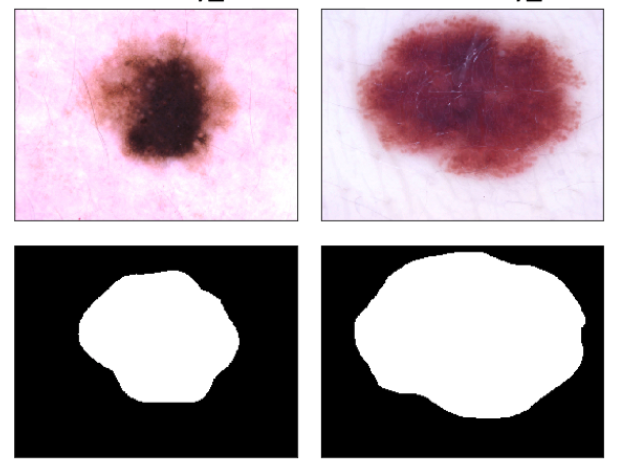
Newton M. Kinyanjui, Timothy Odonga, Celia Cintas, Noel C. F. Codella, Rameswar Panda, Prasanna Sattigeri, Kush R. Varshney NeurIPS Fair Machine Learning for Health Workshop (NeurIPS-W), 2019 We present an approach to estimate skin tone in benchmark skin disease datasets, and investigate whether model performance is dependent on this measure |

|
Rameswar Panda, Jianming Zhang, Haoxiang Li, Joon-Young Lee, Xin Lu, Amit K. Roy-Chowdhury European Conference on Computer Vision (ECCV), 2018 [Project Page] [Supplementary Material] We investigate different dataset biases and propose a curriculum guided webly supervised approach for learning a generalizable emotion recognition model. |

|
Niluthpol C. Mithun, Rameswar Panda, Evangelos E. Papalexakis, Amit K. Roy-Chowdhury ACM Multimedia (MM), 2018 This work exploits large scale web data for learning an effective multi-modal embedding without requiring large amount of human-crafted training data. |
|
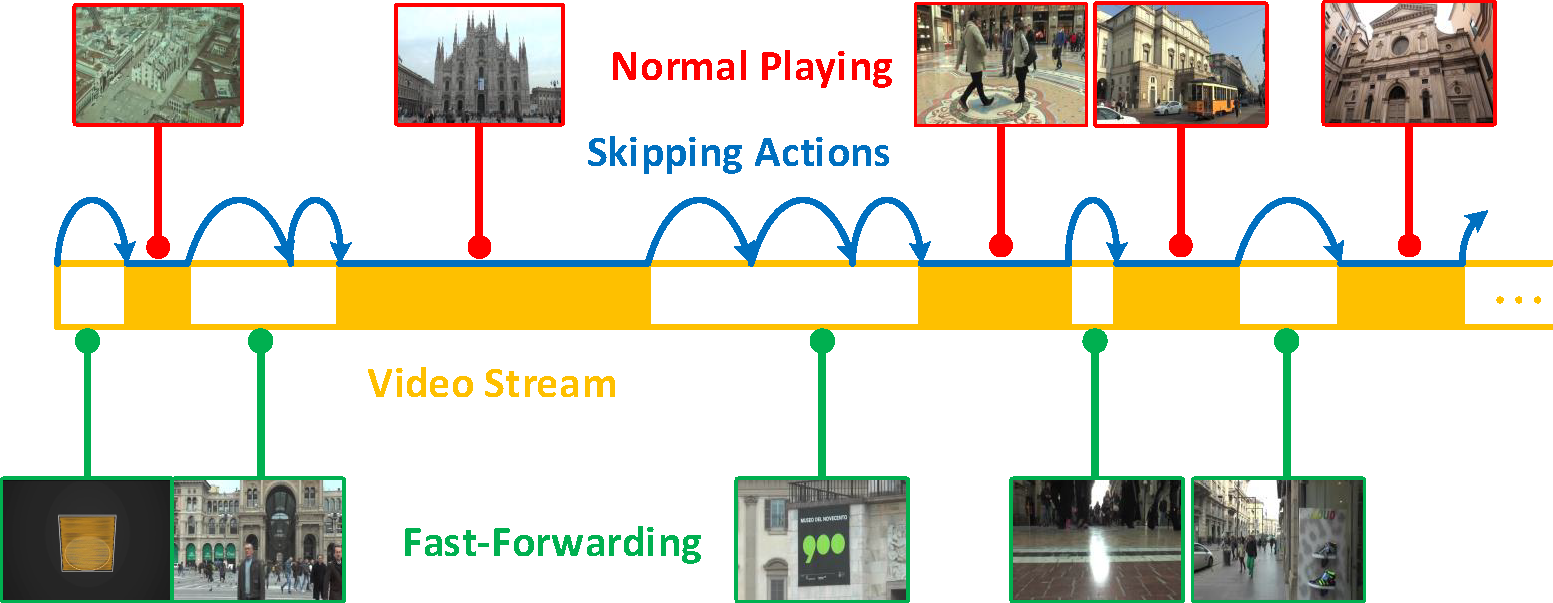
Shuyue Lan, Rameswar Panda, Qi Zhu, Amit K. Roy-Chowdhury IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018 We introduce an online framework for fast-forwarding a video while presenting its important and interesting content on the fly without processing or even obtaining the entire video. |
|
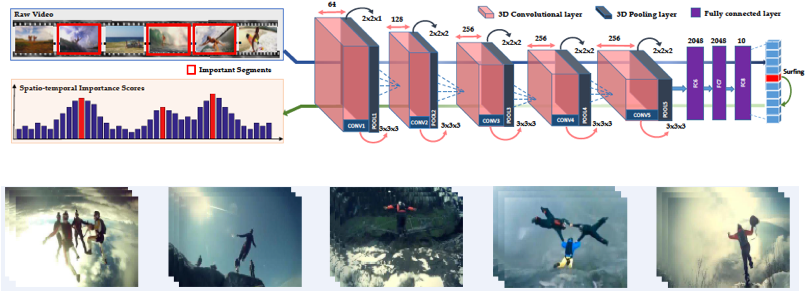
Rameswar Panda, Abir Das, Ziyan Wu, Jan Ernst, Amit K. Roy-Chowdhury International Conference on Computer Vision (ICCV), 2017 We introduce a weakly supervised approach that requires only video-level annotations for summarizing long unconstrained web videos. |
|
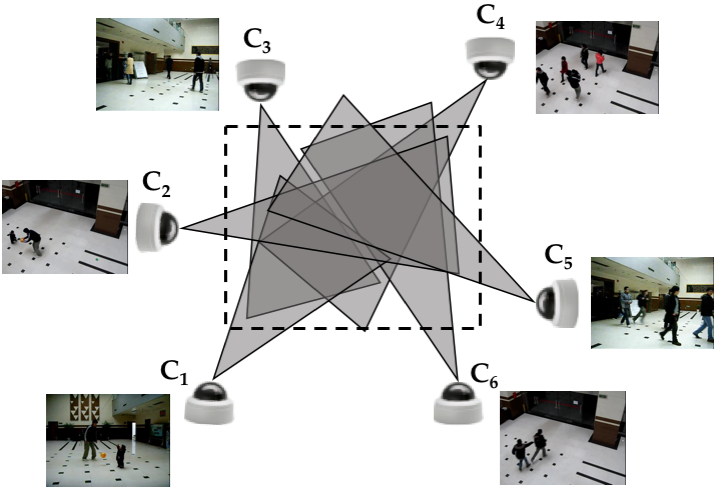
Rameswar Panda*, Amran Bhuiyan*, Vittorio Murino, Amit K. Roy-Chowdhury IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017 We propose an unsupervised adaptation scheme for re-identification models where a new camera may be temporarily inserted into an existing system to get additional information. |

|
Rameswar Panda, Amit K. Roy-Chowdhury IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017 This paper presents a collaborative video summarization approach that exploits visual context from a set of topic-related videos to extract an informative summary of a given video. |
|
Rameswar Panda, Amit K. Roy-Chowdhury IEEE Transactions on Multimedia (TMM), 2017 This paper extends our ICPR 2016 paper providing new theoretical insights with a joint optimization and experimenting on spatio-temporal features and datasets. |

|
Rameswar Panda, Niluthpol C. Mithun, Amit K. Roy-Chowdhury IEEE Transactions on Image Processing (TIP), 2017 This paper introduces a new generalized sparse optimization framework for summarizing multiple videos generated from a video search or from a multi-view camera network. |
|
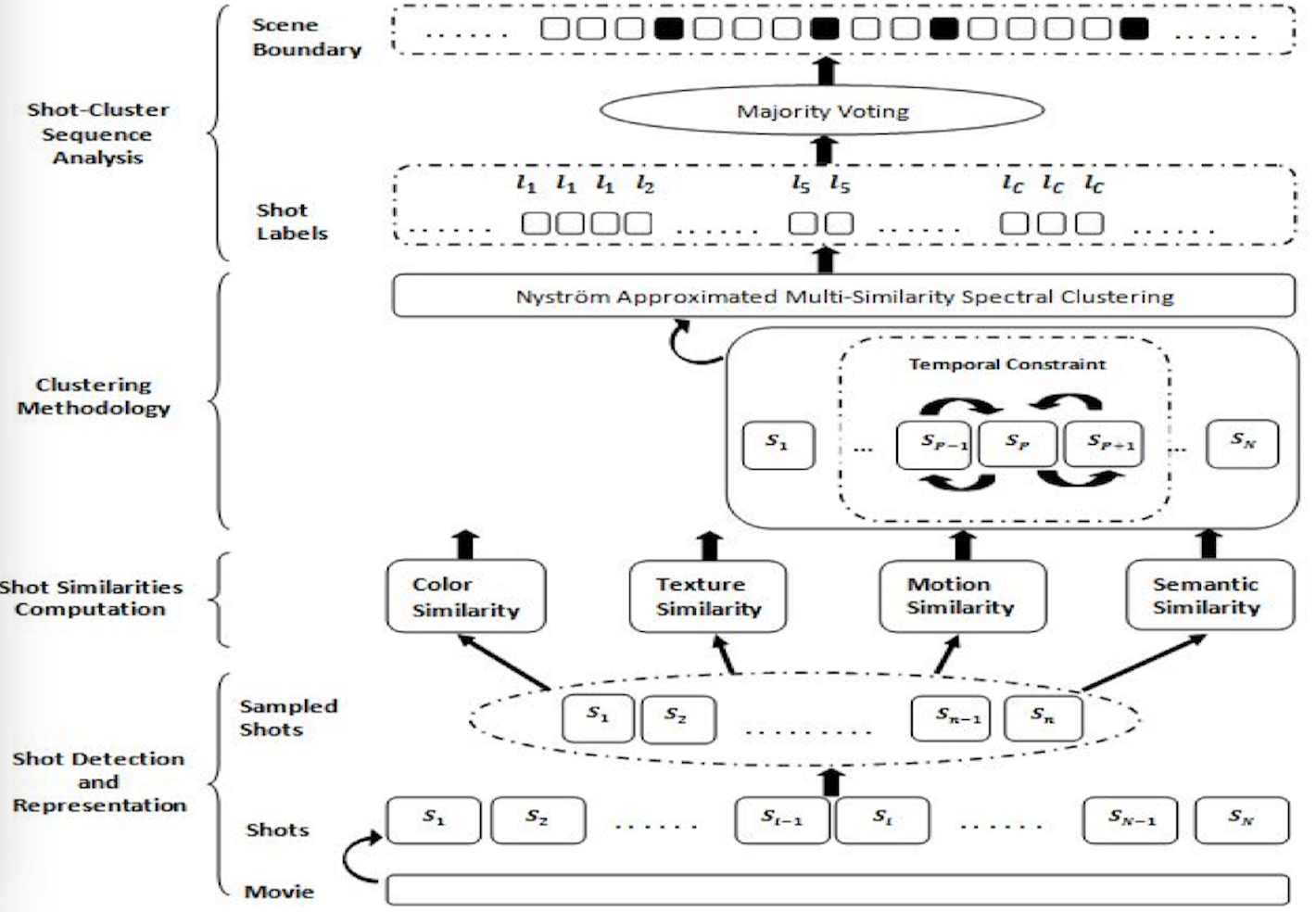
Rameswar Panda, Sanjay K. Kuanar, Ananda S. Chowdhury IEEE Transactions on Cybernetics (TCYB), 2017 We present a fast solution for movie scene detection using Nystrom approximated multi-similarity spectral clustering with a temporal integrity constraint. |
|
Rameswar Panda, Amit K. Roy-Chowdhury IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2017 This paper presents a diversity-aware sparse optimization framework for summarizing topi-related videos generated from a video search. |
|
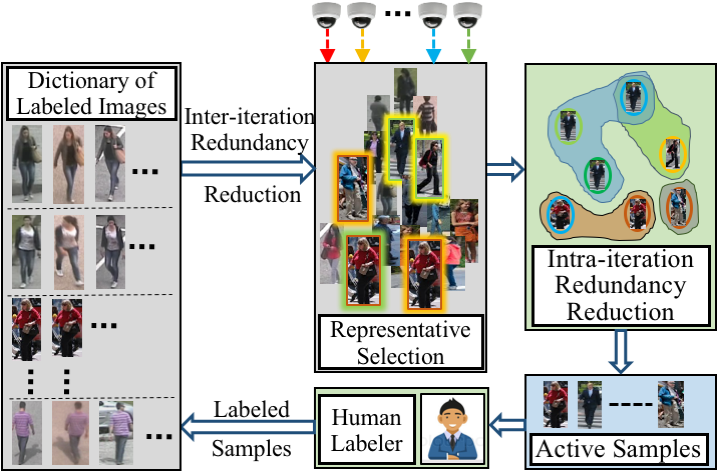
Abir Das, Rameswar Panda, Amit K. Roy-Chowdhury Computer Vision and Image Understanding (CVIU), 2016 We addressed the problem of online learning of identification systems where unlabeled data comes in small minibatches, with human in the loop. |

|
Rameswar Panda, Abir Das, Amit K. Roy-Chowdhury IEEE International Conference on Pattern Recognition (ICPR), 2016 This paper presents a framework for summarizing multi-view videos by exploiting both intra- and inter-view content correlations in a joint embedding space. |
|
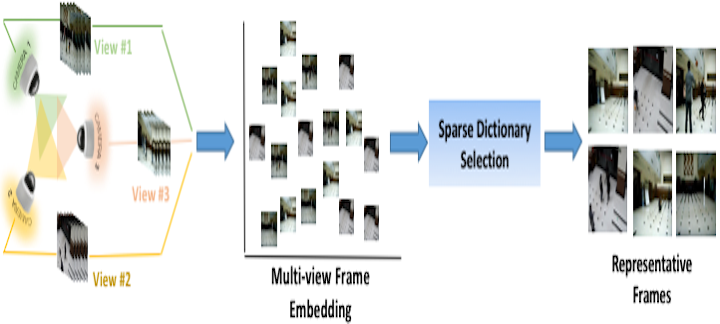
Rameswar Panda, Abir Das, Amit K. Roy-Chowdhury IEEE International Conference on Image Processing (ICIP), 2016 This paper presents a stochastic multi-view frame embedding based on KL divergence to preserve correlations in multi-view learning. |
|
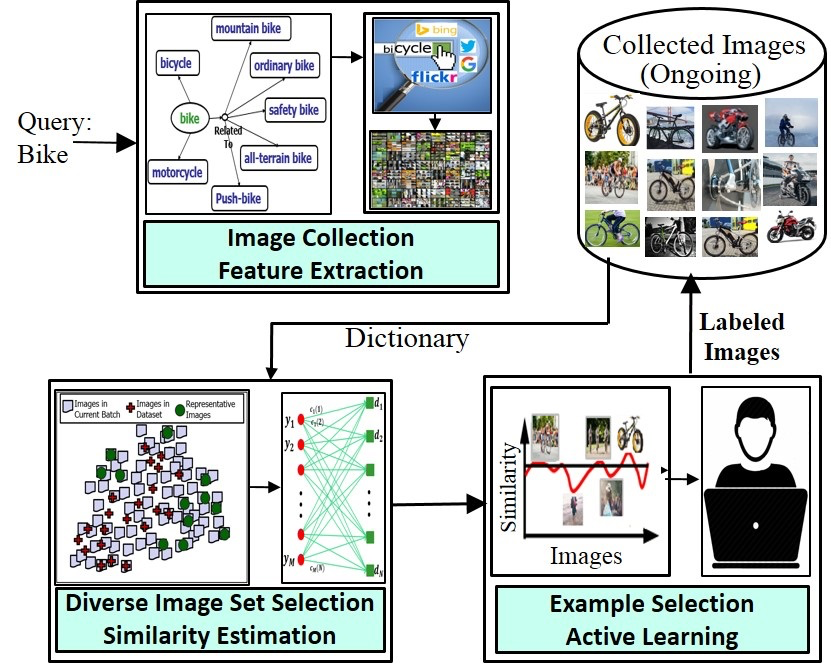
Niluthpol C. Mithun, Rameswar Panda, Amit K. Roy-Chowdhury ACM Multimedia (MM), 2016 This paper presents a semi-supervised sparse coding framework which can be used to both create a dataset from scratch or enrich an existing dataset with diverse examples. |
|
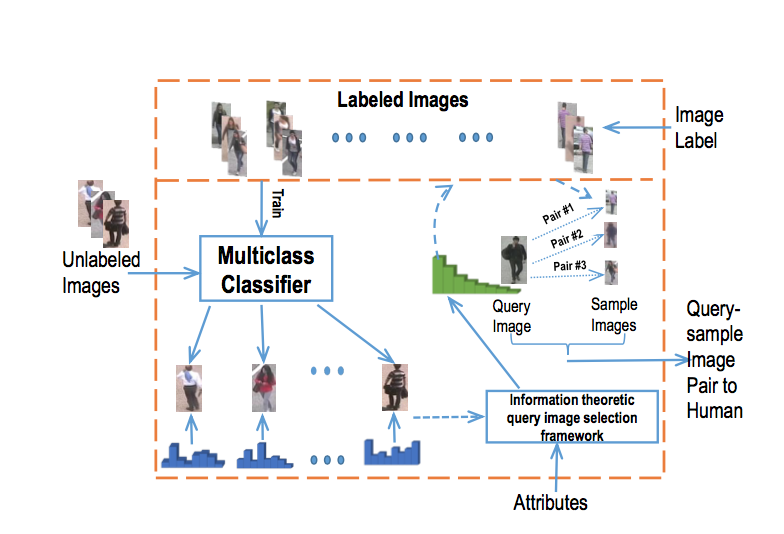
Abir Das, Rameswar Panda, Amit K. Roy-Chowdhury IEEE International Conference on Image Processing (ICIP), 2015 We present a continuous learning re-id system with a human in the loop which not only provides image labels but also improves the learned model by providing attribute based explanations.. |
|
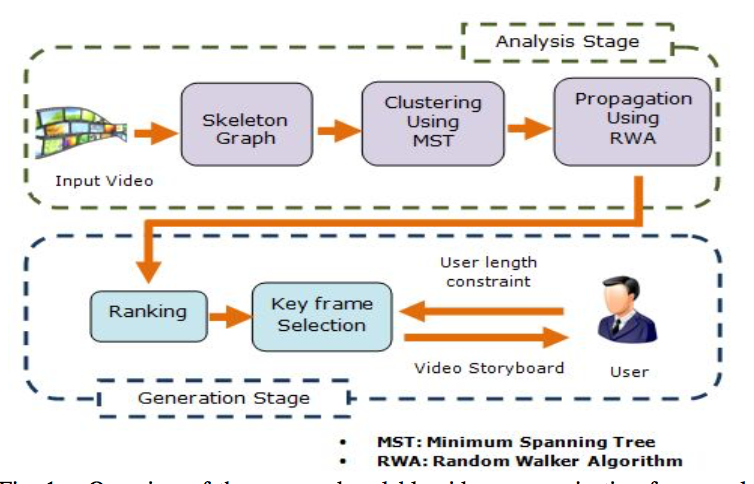
Rameswar Panda, Sanjay K. Kuanar, Ananda S. Chowdhury IEEE International Conference on Pattern Recognition (ICPR), 2014 This paper presents a scalable video summarization framework for both the analysis of the input video as well as the generation of summaries according to user-specified length constraints. |
|
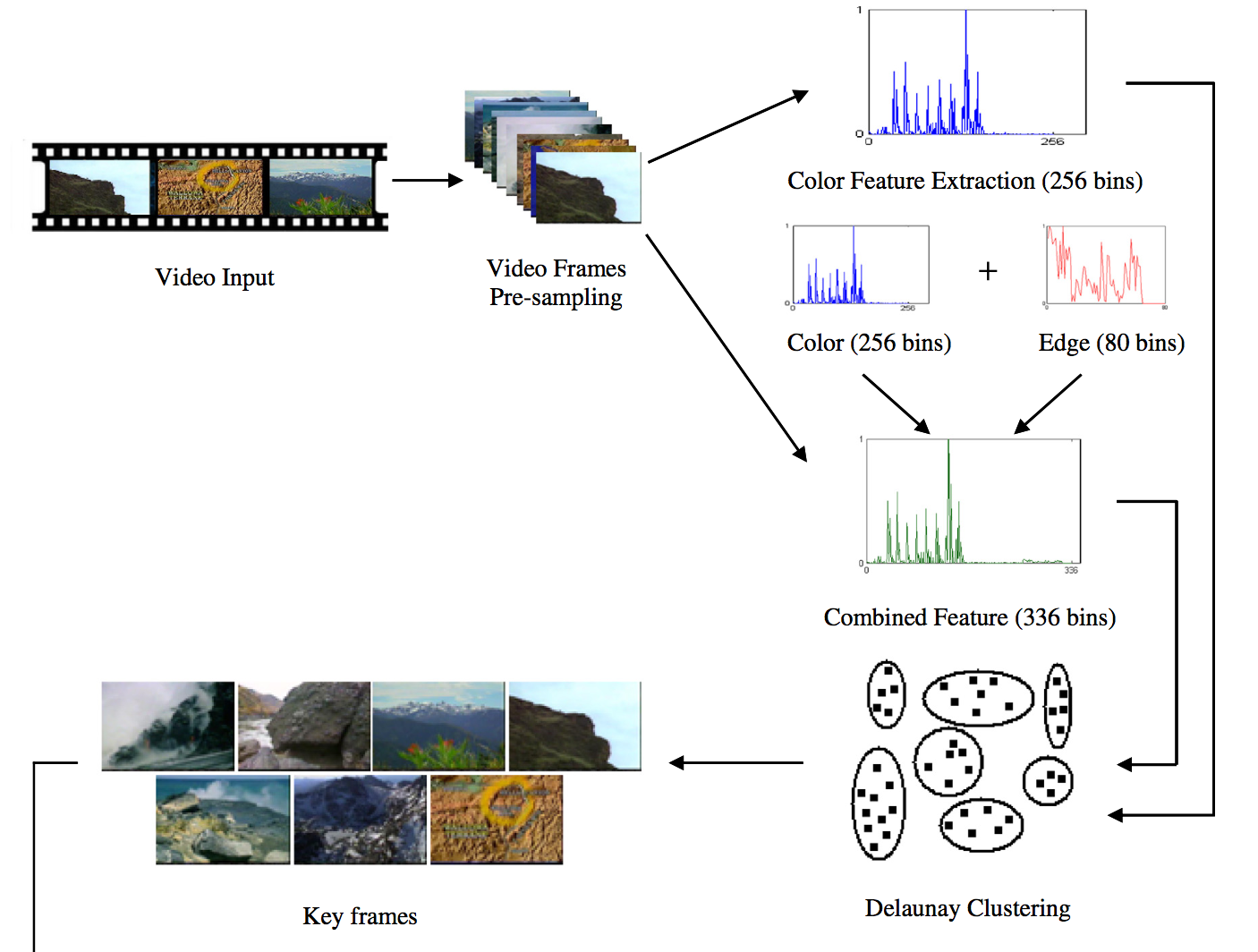
Sanjay K. Kuanar, Rameswar Panda, Ananda S. Chowdhury Journal of Visual Communication and Image Representation (JVCIR), 2013 This paper extends our ICPR 2012 paper providing new theoretical insights and experiments on more datasets including different key frame visualization techniques. |

|
Ananda S. Chowdhury, Sanjay K. Kuanar, Rameswar Panda, Moloy N. Das IEEE International Conference on Pattern Recognition (ICPR), 2012 This paper uses dynamic Delunay grpah clustering for summarizing videos. |
|
|
* Equal Contribution / Website template from this great guy! |